Building a Generative AI CLI with Amazon Bedrock and Go

chat-cli is a project I've been working on for the past couple months. It started out as a way to kick the tires on the now publicly available Amazon Bedrock service, and also as a way for me to learn a bit more about Go, and the AWS SDK for Go version 2. Since then, it has turned into a bit of an exploration into command line interface design, which is pretty interesting to me!
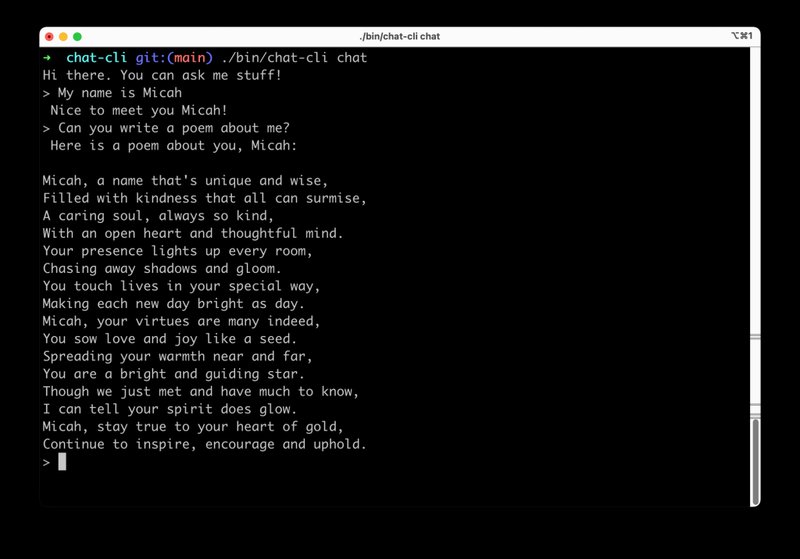
A CLI for LLMs (Micah's Version)
There are plenty of command line interfaces out there for working with large language models (LLMs). I especially like Simon Willison's llm project, which is built in Python and allows for a nice CLI to work with OpenAI LLMs and more. I drew a lot of inspiration from his project, and tried to create something similar for Amazon Bedrock.
In case you are unfamiliar, Amazon Bedrock is a new service from AWS that offers customers "The easiest way to build and scale generative AI applications with foundation models." It provides a unified API to access a growing list of foundation models without having to worry about provisioning infrastructure.
With Bedrock you can currently access foundation models from the following providers:
- Titan from Amazon – (currently in preview).
- Claude from Anthropic
- Jurassic-2 from AI21 Labs
- Command from Cohere
- Stable Diffusion from Stability AI
- Llama 2 from Meta – (coming soon)
Each model has different capabilities and nuances, which I'll describe in more detail below. Except for Stable Diffusion, these are all text based models, which allow you to have contextual conversations, summarize documents, generate new content like blogs or emails, and much, much more. Stable Diffusion allows for image generation from a text prompt.
Bedrock is a quickly growing service, and I'm keen to explore all its bells and whistles in the future, but for now, a simple command line program sounds like a nice way to get to know the service.
Getting Started
Initially my thought was to build a command line program that could talk to Anthropic's Claude in an interactive chat type of interface. Eventually I realized that what I really wanted was a program that could talk to any of the available models with a variety of interfaces and options.
To get started, I wrote a simple program in Go that created a chat style interaction at the prompt. The prompt would capture your input, mold it into the style expected by Claude, and send it up to Bedrock via the AWS SDK for Go.
Creating the chat loop was pretty simple. I wrote a function called stringPrompt that waits for input from the user. This gets called from the main program in an infinite loop, so once you send your prompt and get a response back from Bedrock, you wind up back at the prompt again, waiting for your next input.
func stringPrompt(label string) string {
var s string
r := bufio.NewReader(os.Stdin)
for {
fmt.Fprint(os.Stderr, label+" ")
s, _ = r.ReadString('\n')
if s != "" {
break
}
}
return s
}
Sending a prompt to Bedrock was also pretty trivial. The InvokeModel API method requires a small payload of info related to the model you want to invoke, and the details of your prompt. Within the AWS Console, you can try things out in the Bedrock Playground, which will generate a payload based on the model and settings you've chosen.
resp, err := svc.InvokeModel(context.TODO(), &bedrockruntime.InvokeModelInput{
Accept: &accept,
ModelId: &modelId,
ContentType: &contentType,
Body: []byte(string(payloadBody)),
})
To keep things simple, I hard-coded most of the options based on my experience in the Bedrock Playground, and focused on designing the prompt format to look like what Claude was expecting. Claude has the idea of "Stop Words" which are used to give meaning to the conversation you are sending. For example, the default stop word is /n/nHuman: so your prompt needs to include this to separate your prompt from the responses from Claude.
There are lots of additional options and features for interacting with Claude, which you can read about on their website. I believe this is called "prompt engineering!"
It's alive!
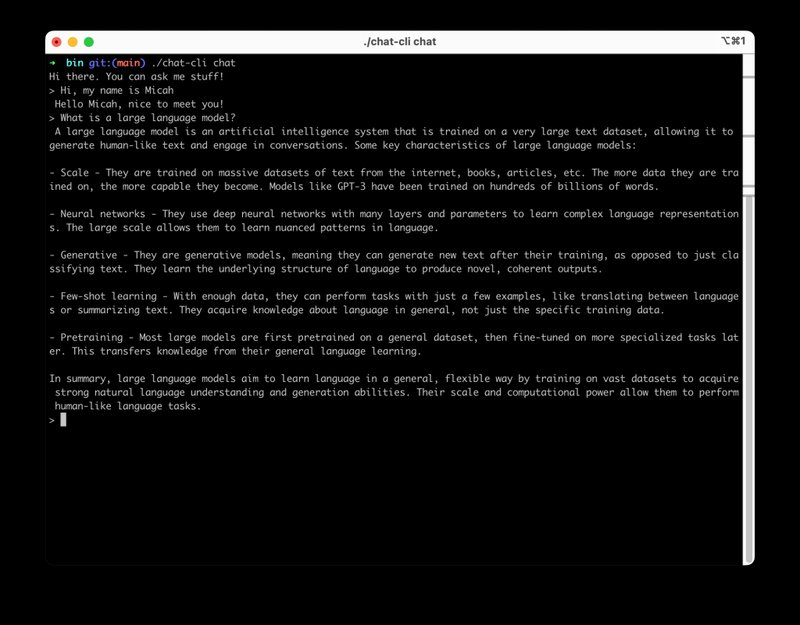
Once I had this all wired up and working, I noticed a couple details.
- Claude (or any model for that matter) only knows about whatever you send it each time. It doesn't have a persistent memory of your conversation. So while sending "Hi, My name is Micah" might result in "Hi, Micah." as a response from Claude, it won't remember that context the next time you send a message, unless you include it in the prompt.
- The
InvokeModelAPI is a synchronous request, which means you might wind up waiting for a good amount of time for a response to arrive, depending on the nature of your prompt.
To deal with #1 I investigated two different approaches. The first was to simply keep the running conversation in memory, stored as a string. While this could eventually run up against some hardware limits for the user, it likely will work for most conversation sessions. The second approach is to store the conversation transcript to disk and offer a way to load it back into memory. This seemed like a good idea when I started working on it, but in practice, I am unsure if it's really all that useful. Claude generates responses based on the text you send it, so it really becomes a matter of how much context you need to give it to get the kind of response you'd like to see. Remembering my name so that it can then use my name to generate a poem is nice, but it may not be important to remember every single interaction in the conversation. I'm still struggling to understand how to deal with this issue. Another side effect this brings up is that your conversation transcript will just grow and grow over time, which means you will begin to consume more and more input tokens, which have a limit, depending on which model you are using. This is especially problematic when you begin to want to include documents as part of the context as you need to carefully manage how many copies of the same text are sent to the LLM.
To deal with #2 I also investigated two different approaches. The simplest, dumbest solution was to add some kind of "wait state" indicator. Think spinning beach ball. For this, I found a nice Go package called "Spinner" which makes it really easy to add some kind of user feedback while you wait for a response. This is nice, but the user is still waiting for a response. The second approach was to implement the InvokeModelWithResponseStream API. This API appeared to do what I wanted by sending the response back in chunks rather than all at once, so that the user begins to see feedback right away. The only issue was it leveraged Go Channels, which was something I wasn't familiar with. So, I had to learn all about Go Channels.
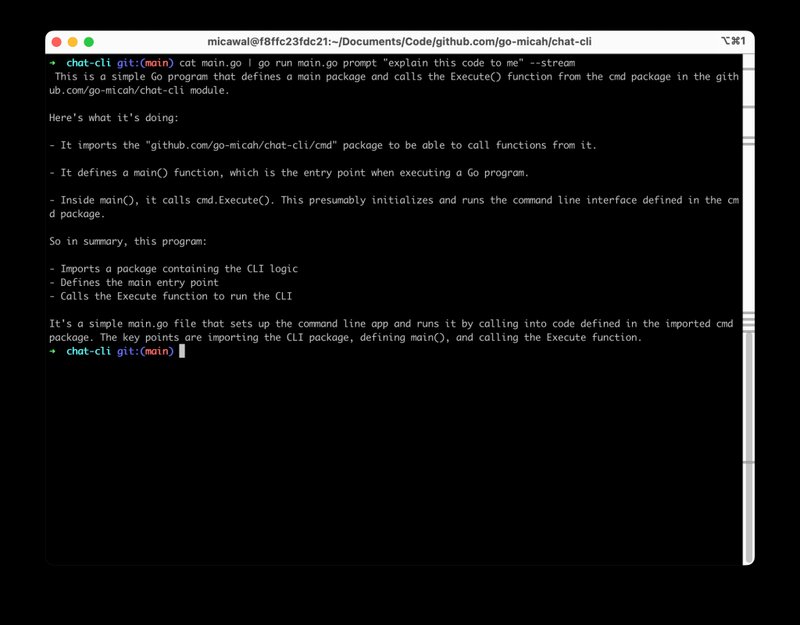
Evolving the project
After getting things more or less working, I decided I wanted to make two major changes to progress the project forward.
So far my project was nothing more than a single main.go file. I knew I'd need to think a little more critically about the overall design of the software to accommodate the evolution of the project as I continued to experiment and try new things. For this, I turned to the very lovely Go packages Cobra and Viper. Cobra is a framework for building CLI tools in Go. It provides all the structure and tooling to set up a CLI program quickly, and allows you to easily add new commands, flags and all sort of options as the program grows over time. Viper is for dealing with configuration. The two packages work hand in hand and together allow me to not have to think too hard about how to build a CLI tool in 2023!
I spent a few hours re-factoring my project to work with Cobra and Viper and then began designing the overall interface. Through this process I realized a couple of things.
- I wanted to offer multiple commands instead of just a chat program. So far I have created a chat command and a prompt command. The chat command does what I had already done, which is to put the user into an interactive chat session. The prompt command allows to user to simply send a single prompt.
- I also realized that I really wanted to allow users to access any of the LLMs available in Bedrock. Cobra and Viper offered me an easy way to add feature flags, so I set about implementing the rest of the models I had available.
Not all LLMs are created equal
While Amazon Bedrock offers a unified API for interacting with LLMs, each LLM has its own unique characteristics. This means that a program that allows a user to interact with multiple LLMs will need to take these unique characteristics into account. For example, not all LLMs are capable of sending a streaming response. As well, each LLM has its own levers you can pull to adjust parameters like Temperature, Top P, or Top K. Since they are all a little different, I basically had to write unique types in Go for each one I wanted to support.
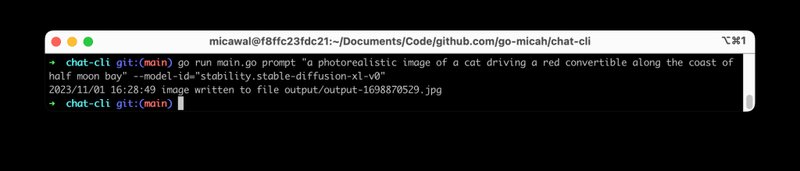
Beyond the various nuances of each LLM, Stable Diffusion is an entirely different animal. Instead of receiving a text based response, Stable Diffusion sends back image data. So, I had to think through how to deal with that, and save the results to disk. It wasn't too hard to figure out, but I did have to add logic to my code to give an error when the user was trying to do something that didn't make sense with Stable Diffusion, like starting an interactive chat session.

The current state of things and things to come
The program is now in what I would call a "working" state. You can clone the repository and compile it yourself and give it a go. Here is what you can currently do:
- You can enter an interactive chat session with Anthropic Claude.
- Within an interactive chat you can save and load your chat transcript to disk
- You can send a single prompt to Bedrock from the command line
- You can use the
--model-idflag to select which supported LLM you wish to use - You can use the
--streamflag to get a streaming response from a supported model - You can pipe a file in from
stdinand combine with a prompt to do things like "explain this document to me" - You can use Stable Diffusion from the command line to generate and save images to disk
I have a number of thoughts for future additions, but here are the near terms updates I plan to make:
- Ability to send a source image to Stable Diffusion
- Ability to save settings to a configuration file
- Un-hard-code all the LLM settings and create flags for each of them
- Implement additional functionality available through the SDK like listing of available models
- Setting up a documentation website for the project
- Figure out how to sign binaries for easy install
Help!
Overall this has been a fun project. I've learned quite a bit about Generative AI, Large Language Models, Foundation Models, and have had some fun learning more about Go and building command line interfaces. I'd love some help! If you'd like to try chat-cli on your own, contribute to the code, suggest ideas or comment on my coding skills, please feel free to do so right here.